Slurm
Table of Contents
So recently I was tasked to set up a Slurm cluster for bioinformatics workloads, and I thought it would be a good idea to share some notes about the installation and configuration process.
So in short, before we start, what is Slurm?
Slurm is an open-source, fault-tolerant, and highly scalable cluster management and job scheduling system for large and small Linux clusters. It is used by many of the world’s supercomputers and computer clusters.
Before we have Slurm, the bioinformaticians used to access the servers directly via SSH, open a screen/tmux session, and run their jobs directly on the servers. This approach has several drawbacks:
-
Resource management: Without a job scheduler, it is difficult to manage and allocate resources efficiently. Suppose you have a server with 128Gb of RAM, and your job requires 32Gb of RAM to run, so you think “I can run 4 jobs in parallel”, but if another user is running a job that requires 64Gb of RAM, your job will fail due to insufficient resources.
-
Job prioritization: Without a job scheduler, it is difficult to prioritize jobs based on their importance or urgency. This can lead to situations where less important jobs are running while more important jobs are waiting in the queue.
-
Queue management: Without a job scheduler, the users have to manually monitor and send new jobs when the previous one finishes. Now imagine that your job takes 16 hours to run, will you SSH into the server at 2AM to send a new job? Probably not, so your jobs will be delayed, and the server will just sit idle while you sleep. This is inefficient.
With that in mind, it is very clear that we need a job scheduler, and Slurm is a great choice for that.
#
Slurm operation
##
The main workflow
The main workflow of Slurm is quite simple:
-
The user creates a special bash script with the job parameters and the commands to run. Here is an example of such a script:
#!/usr/bin/env bash #SBATCH --job-name=my_job_name # Job name #SBATCH --output=output.txt # Standard output file #SBATCH --error=error.txt # Standard error file #SBATCH --partition=partition_name # Partition or queue name #SBATCH --nodes=1 # Number of nodes #SBATCH --ntasks-per-node=1 # Number of tasks per node #SBATCH --cpus-per-task=1 # Number of CPU cores per task #SBATCH --time=1:00:00 # Maximum runtime (D-HH:MM:SS) #SBATCH --mail-type=END # Send email at job completion #SBATCH --mail-user=your@email.com # Email address for notifications # Your commands go here module load python/3.8 python my_script.py -
The user submits a job to the Slurm controller using the
sbatchcommand -
The Slurm controller adds the job to the queue and assigns it a job ID
-
The Slurm controller schedules the job to run on a compute node when resources are available
-
The compute node executes the job and sends the output back to the user
The user can monitor the job status using the squeue command.
The administrator can manage the jobs using the scancel command to cancel a job, or the scontrol command to modify a job.
##
Basic commands
Check the cluster status:
sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
debug up 30:00 2 idle node[01-02]
batch up 2-00:00:00 4 alloc node[03-06]
List running and pending jobs:
squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
1001 batch test.sh alice R 0:15 2 node[03-04]
1002 debug script bob PD 0:00 1 (Priority)
Run a interactive job session:
srun --partition=debug --nodes=1 --ntasks=1 --time=00:30:00 --pty bash
Cancel a job:
scancel <job_id>
#
Slurm components
The main components of Slurm are:
- slurmctld: The Slurm controller daemon, which is responsible for managing the cluster and scheduling jobs. It runs on the controller node.
- slurmd: The Slurm daemon, which is responsible for executing jobs on the compute nodes. It runs on each compute node.
- slurmdbd: The Slurm database daemon, which is responsible for storing job and user information in a database. It is optional and can run on a separate node.
#
Installation
The installation process is quite straightforward, and you can find the official documentation here.
In my case, I used a Debian 13 VM as a all-in-one controller and multiple physical Debian 13 servers as compute nodes. In a more robust setup, you would probably want to have a separate database server, multiple controllers for redundancy, but for this example, since the cluster is relatively small, we will use the simplest configuration.
Since the configuration is the same for all nodes, this is a perfect scenario to be automated by Ansible, I will not cover the Ansible part here, but I will show you the main gotchas that I encountered and would save a lot of time.
#
Tips and tricks
##
Find real user documentation
Since Slurm is very popular in the academic world, there are many universities that have their own documentation, it is a very good starting point to find real user documentation, here are some examples that were very helpful to me:
Advanced Research Computing at Hopkins
##
Configless mode
Since Slurm 20.02, it supports a configless mode, which means that you don’t need to create a /etc/slurm/slurm.conf file on each node, instead, you can use the slurmctld to distribute the configuration to all nodes.
This is a great feature, and it simplifies the installation process a lot. The official documentation is here.
It just depends on a very simple DNS SRV record, so make sure you have that set up correctly. Take this example, and adapt it to your setup:
_slurmctld._tcp 3600 IN SRV 10 0 6817 slurmctl-backup
_slurmctld._tcp 3600 IN SRV 0 0 6817 slurmctl-primary
##
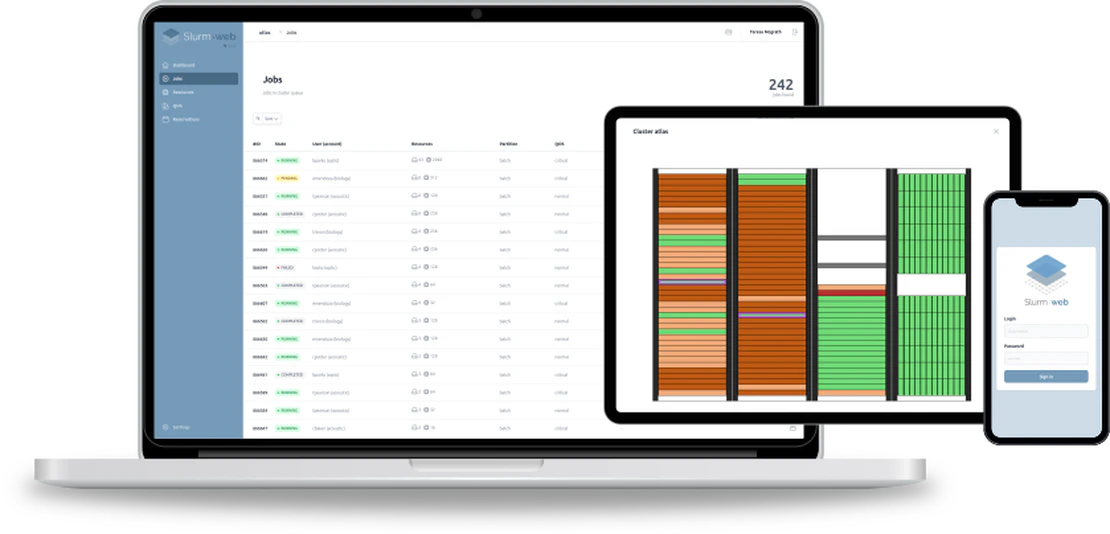
Slurm-web
Slurm-web is a web interface for Slurm, which allows you (and your users!) to monitor and manage the cluster from a web browser. You can find the official documentation here.
##
slurm-mail
Slurm-Mail is a drop in replacement for Slurm’s e-mails to give users much more information about their jobs compared to the standard Slurm e-mails. You can find it on Github.
##
Power saving
Now this is a feature that I was not aware of, but Slurm has a built-in power saving feature, which allows you to automatically power on/off compute nodes based on demand.
It relies on scripts that you need to provide, one for powering on a node, and another for powering off a node. You can find the documentation here.
In my case I adapted the scripts from here to use IPMI to power on/off the nodes.